About two weeks ago, Virdata released a set of patches for Apache Spark enabling Spark to work on Mesos with Docker bridge networking. We are using these in production for our multi tenant Spark environment.
§SPARK-11638: Spark patches
All patches for all components described below are available in Spark JIRA. We’ve released patches for all versions of Spark available at the time of creating them - from 1.4.0 to 1.5.2. We have also released patches for Akka 2.3.4 and Akka 2.3.11; these are required to make this solution usable.
What has not been released with the patches is the complete minimum example of how these can be verified. This post serves as a missing part.
All instructions on how to build Spark and Akka with patches applied can be found at the end of this post.
§Scenario and sources
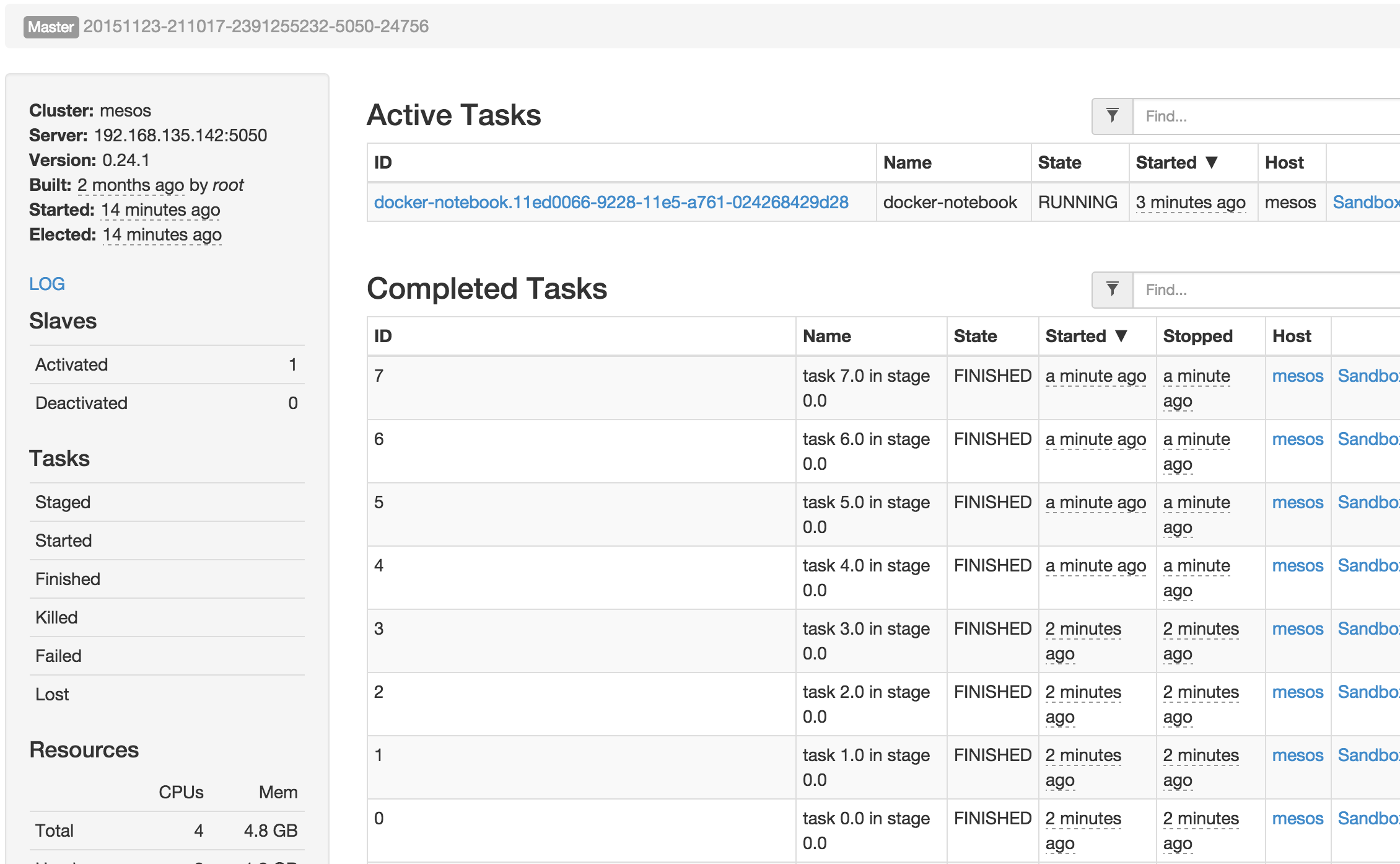
The scenario: setting up Spark Notebook running in Docker container, bridge networking on Mesos. Spark notebook, once a document is opened, starts Apache Spark Master process. Executing Spark code, schedules tasks on the same Mesos the notebook server is running on.
The observed outcome: executors communicate back to the master, inside of the Docker container.
All programs discussed below are available on github. Let’s go through a short summary of what is happening…
§Setting up the machine
For the simplicity, I assume clean Ubuntu 14.04 installation. These instructions should work without any issues on EC2, SoftLayer or any other cloud provider.
My VM is a 4 CPUs, 8GB RAM VMWare Fusion machine.
First, the machine has to be set up:
- checkout the repository and put them in
~on your test machine (cd ~ && git clone https://github.com/virdata/mesos-spark-docker-bridge.git .) - build relevant Spark version with the patch from Spark JIRA (all examples assume
1.5.1) - build relevant Akka version for your Spark version (in case of this example it always
2.3.11, spark-notebook excludes any other Akka and assumes2.3.11) - put the
akka-remote_2.10-2.3.11.jar, result of the build, in~ - put
spark-core_2.10-1.5.1.jarandspark-repl_2.10-1.5.1.jar, result of the build, in~ - execute
setup.sh
The most important things to know:
- OpenJDK 7 will be used
- Mesosphere apt repo will be added
- Mesos
0.24.1with Marathon0.10.1is used - Mesos agent runs on the same machine as Mesos master
- latest docker is installed
- local installation of ZooKeeper is used
/etc/mesos.agent.shfile is created, explained below- Spark stock release is downloaded and stored on the machine to be used for executors
- patched Akka and spark JARs required only for the master, executors can happily use the stock release
§/etc/mesos.agent.sh
The container has to know what is the IP address of the Mesos agent the container’s task is running on. Mesos, nor Marathon, currently does not provide this information. When a task is scheduled, there is no way to know which agent the task is going to end up on until the task is running. This make it impossible to give the agent’s IP at task submission time. /etc/mesos.agent.sh is given to the container as a Docker volume. This file needs to exist on every agent node. In this example, it is not really necessary. The master and agent are the same node. The file is provided for clarity and makes it possible to use multi node setup.
This step takes takes about 15 minutes on my VMWare Fusion VM. When finished, Mesos UI and Marathon UI should be reachable:
- Mesos: http://mesos:5050
- Marathon: http://mesos:8080
mesos host may have to be added /etc/hosts file.
§Spark notebook Docker image
In theory, a snapshot version of Data Fellas notebook should work but, if there are any doubts, build-docker-image.sh program should be used to get an upstream version of the Docker image.
The most important things to know:
- git master version of the code is used
- base image changed to
ubuntu:trustyandentrypointchanged so it is possible to run the container withdocker -ti ... /bin/bash
This will take about half an hour to build. The andypetrella/spark-notebook:0.6.2-SNAPSHOT-scala-2.10.4-spark-x.x.x-hadoop-2.4.0 image should be on the list after executing docker images command.

§Run ~/run-task.sh
This will request a Mesos task with Marathon. There are 6 ports being requested, the order:
9000: Spark notebook server user interface9050: LIBPROCESS_PORT6666: spark.driver.port6677: spark.fileserver.port6688: spark.broadcast.port6699: spark.replClassServer.port
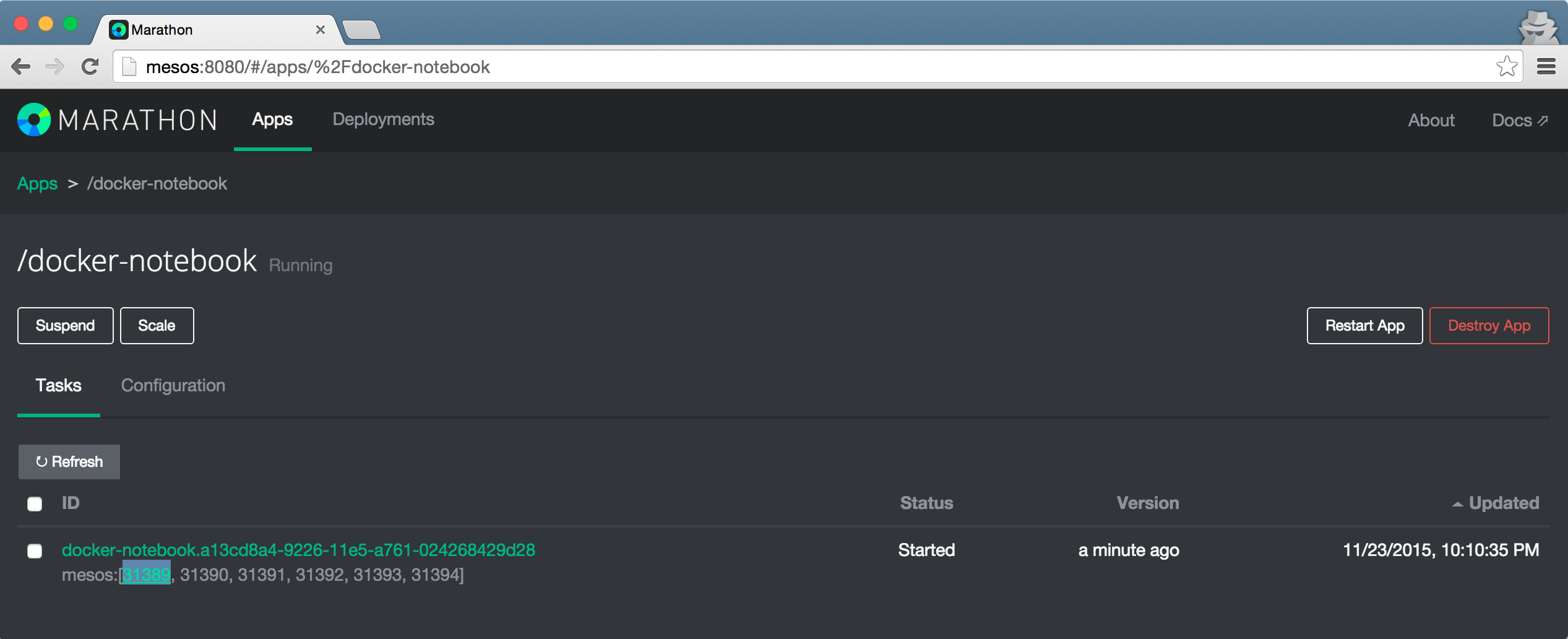
The command used in the container is $MESOS_SANBOX/run-notebook.sh. What happens inside is the following:
- source
/etc/mesos.agent.shto learn the IP address of the host agent - set
LIBPROCESS_*properties, the advetise IP is set to the host IP and advertise port is$PORT_9050(the port assigned by Mesos); Mesos will now correctly return offers to the container SPARK_LOCAL_IPis set to the container’s IP addressSPARK_PUBLIC_DNSandSPARK_LOCAL_HOSTNAMEare set to the hostname of the agent- next, agent’s hostname is added to the container’s
/etc/hostsfile; this makes it possible for Spark to bind all services to the agent hostname so it can be correctly advetised to the executors; for thespark.driver.port/spark.driver.advertisedPort, the akka patch is required CLASSPATH_OVERRIDEScontains 3 JARs: patchedakka-remote, patchedspark-coreandspark-repl; this env variable was added tospark-notebookjust to make these patches work; the most important thing to know: these 3 JARs have to be on the class path before any other Spark / Akka jars; if loaded first, the JVM will use them over any other classes from any other JARs- side note: Zeppelin has recently added support for
ZEPPELIN_CLASSPATH_OVERRIDESenvironment variable
The final step is starting the notebook server. Worth noticing are all settings ending with advertisedPort. This is the main part of the Spark patch.
§To verify
Create a new notebook and execute the following:
val rdd = sparkContext.parallelize(Seq(1,2))
rdd.count()
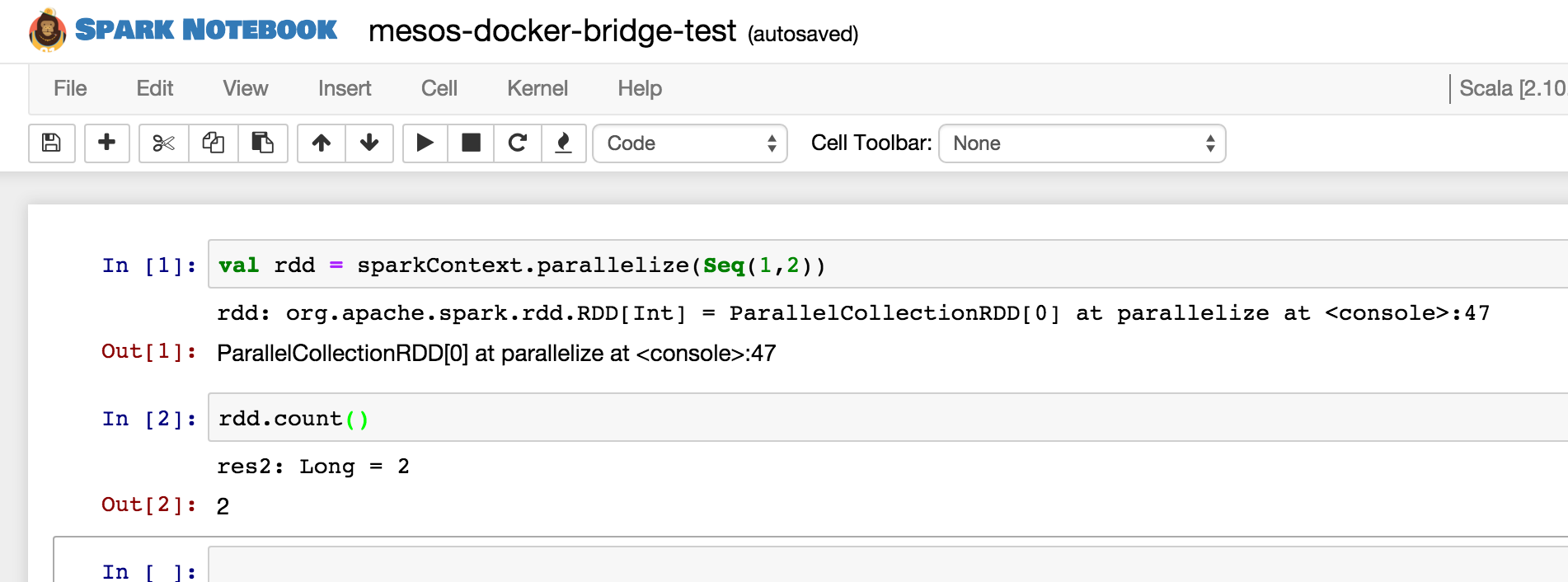
Rather simple but… The executors will be scheduled on the same Mesos cluster the notebook server is running on. The executors will successfully publish the results bask to the master running in the Docker container.
With the fine-grained mode, it sometimes happes that the tasks are stuck in STAGING for a long time and the whole job fails. If this is the case during the test, repeat the test with:
spark.mesos.coarse = true
using notebook metadata. It is important to remember that notebooks saved on one server carry over the Spark configuration in them. As such, it is not safe to import a notebook from another notebook server to execute the test. Please use a new, clean notebook.
Perfomance-wise, no real numbers to share but we are getting within ~95% of the usual setup with coarse mode.
§Components
§Patched Akka
AKKA_VERSION=2.3.11
git clone https://github.com/akka/akka.git
cd akka
git fetch origin
git checkout v${AKKA_VERSION}
git apply path/to/${AKKA_VERSION}.patch
sbt package -Dakka.scaladoc.diagrams=false
§Patched Spark
SPARK_VERSION=1.5.1
git clone github.com/apache/spark.git
cd spark
git fetch origin
git checkout v{$SPARK_VERSION} # from the tag
git apply path/to/${SPARK_VERSION}.patch
./make-distribution ...
§Akka versions
2.3.4:- Spark
1.4.0 - Spark
1.4.1 2.3.11- Spark
1.5.0 - Spark
1.5.1 - Spark
1.5.2
§Comments? Thougths?
Thoughts and comments are appreciated! Please use github issues for communication.
Happy coding!