
Permissions management is an interesting topic. Modern applications are often complex beasts. It doesn’t take much time to hit the point where certain functionality must be allowed only to the selected users or access to a resource should be granted only under certain conditions.
Building a flexible permissions management system is not easy. They tend to be tightly coupled with the business logic and executed every time a decision whether to grant or deny access is required. There are as many requirements as software systems out there. A permissions management systems must also perform. If decisions are to be made often, the latency to make a decision must be minimal.
ORY Keto is one of the ORY platform components and a few days ago it has seen a major upgrade. Versions 0.6.0-alpha.1 is a complete reimplementation of Keto and is marketed as the first open source implementation of Zanzibar: Google’s Consistent, Global Authorization System[1].
From the Zanzibar abstract:
Determining whether online users are authorized to access digital objects is central to preserving privacy. This paper presents the design, implementation, and deployment of Zanzibar, a global system for storing and evaluating access control lists. Zanzibar provides a uniform data model and configuration language for expressing a wide range of access control policies from hundreds of client services at Google, including Calendar, Cloud, Drive, Maps, Photos, and YouTube. Its authorization decisions respect causal ordering of user actions and thus provide external consistency amid changes to access control lists and object contents. Zanzibar scales to trillions of access control lists and millions of authorization requests per second to support services used by billions of people. It has maintained 95th-percentile latency of less than 10 milliseconds and availability of greater than 99.999% over 3 years of production use.
I have been using previous Keto versions for some R&D work. The new version has sparked my interest because the firebuild system I am working on is going to be in need of a permissions system at some point in time.
To better understand the new Keto, I wanted a simple, easy to follow scenario so a judgement can be formed quickly.
In one short sentence: it was very easy and it’s impressive!!
§the scenario
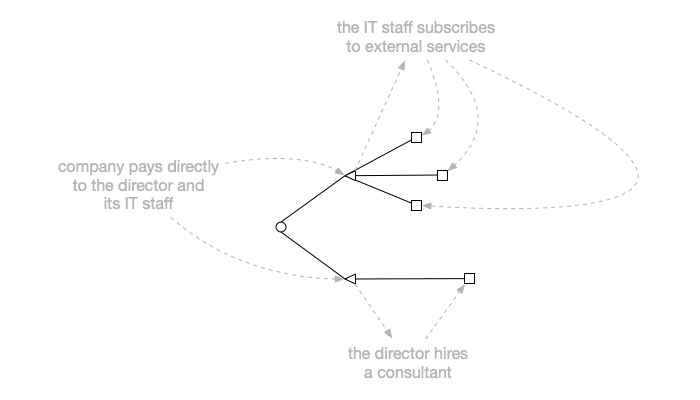
The scenario I was evaluating:
- a company employs a director and IT staff
- the director contracts a consultant
- the IT staff subscribes to external services
Find out what the company pays for directly and indirectly.
Here’s the rough diagram:
§ORY Keto in Docker Compose
I have previously written about my reference ORY Docker Compose[2] and that is what I’m using further. To start the local installation, assuming the containers are already built, as explained in the repository readme[3]:
|
|
The new Keto version exposes two API servers:
- the write API: default port is
4467 - the read API: default port is
4466
Before we can start querying Keto for a decision, we have to create a few relation tuples[4].
Keto does not try understanding our data, it infers the decision by inspecting and traversing tuples it knows.
Relation tuples can be created using cURL via the write API. The Compose setup publishes both Keto APIs so we can start like this:
|
|
|
|
The associations above imply that the company pays for the director and the IT staff. We could model it like this:
|
|
That subject means: the company pays for anybody it employs. Let’s see this in action by executing this request against the read API:
|
|
The output is:
|
|
Now, the IT staff subscribes to AWS, Dropbox and GCP. These relations could be modelled like this:
|
|
As these will bear the cost to the company, the JSON report should list them and can be done with this new relation tuple:
|
|
That means: the company pays for everything the IT staff subscribes to. If we execute the /expand call again, the output will be:
|
|
Pretty cool, regardless of how many services the IT staff would subscribe to in the future, they will get listed in the output!
Knowing about the cost of a consultant contracted by the director could be modelled in the following way:
|
|
|
|
|
|
And if the director decides to contract a solicitor?
|
|
the existing relation already covers that:
|
|
|
|
Very neat. At some point, we might want to have an answer to the following direct question:
does the company pay for the consultant?
|
|
To which the answer is:
|
|
If we ever had to understand what relation causes the company to pay for the consultant, we would use the expand call with sufficient depth.
§notes on the examples
The examples use literal object identifiers for readability purposes. Keto documentation suggests using UUIDv4 or SHA-1 hashes instead. The concept is better explained on this page[5].
§conclusion
This very simple example shows in just few steps how awesome the new version of Keto is.
The API is very simple to use and understand. The flexibility and applicability is endless.
This is something what will greatly benefit firebuild and I am sure we will see Keto being used all over the place.
The ORY team deserves huge applause for making this technology so easily approachable.